Cross Validation
# Tag:
- Source/KU_ML
toc test
Cross Validation
주어진 데이터셋을 train data와 validation data로 나누는 방식을 반복하여서 최고의 효율을 가지는 parameter를 찾는 방법.
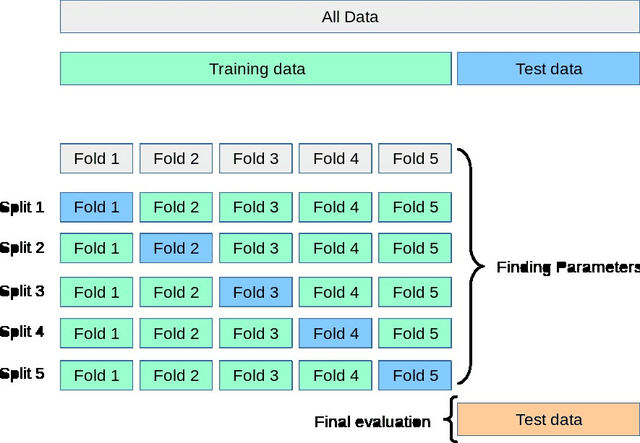
K-Fold Cross validation
데이터를 의 등분으로 쪼개 를 만든다. 그 중 하나는 Validation 데이터로 이용하고 나머지는 Train Data로 활용한다.
이를 번 반복하면서, Validation Data를 바꿔나가면서 그 error rate를 평균내 error를 측정한다.
Validation Data를 다양하게 바꾸어 가며 성능을 측정하므로 더 정확성이 높지만, 계산량이 높아진다는 단점이 존재한다.
- 데이터가 많다면 를 작게 한다.
- 데이터가 적다면 를 크게 한다. 더 작게 쪼개야 Train Data를 더 충분히 학습 가능하다.
- : Leave-one-out이라고 하며, 이는 최악의 경우가 된다.
- : Leave-one-out이라고 하며, 이는 최악의 경우가 된다.
5x2 Cross validation
5번의 2-fold Cross Validation을 수행하는 방법.
데이터를 2-fold로 나누어 cross validation을 수행하고, 이를 5번 반복할 때마다 새롭게 shuffle한다.
이 때, 데이터 간 class 비율을 원본 데이터와 동일하게 fold로 나눈다. 이를 strafication이라고 하며, 이를 통해 각 fold에서의 편향을 줄일 수 있다.