EM
- or
- Expectation Maximization,
- 기대값 최적화
# Tag:
- Source/KU_ML
EM(Expectation Maximization)
Semi-Parametric Methods는, 어떠한 확률 분포를 안다고 가정하고, 그에 대한 Random Variable인 Latent(hidden) Variable를 찾아가는 방법이다.
Parametric Methods처럼 확률 분포를 아는 것도 아니고, 그에 대한 Latent Variable(즉, parameter)도 모른다면 확률 분포를 가정하여서 Parameter를 찾아나가는 과정이다.
Random하게 만들어진 initial Latent Variable이라도, 가정한 확률 분포에 대해 Likelihood를 높여나가는 것을 반복하면 최적의 Latent Variable을 찾을 수 있음에 대한 이론을 바탕으로 만들어진 Method이다.
EM은, latent varaible 에 대해, 라는 Mixture Model을 가정하고, Likelihood에 대한 기댓값을 최대화하면서 추정해나가는 과정이 된다.
추정 과정은 Train Data를 이용해 이루어진다.
Problem when Using MLE
위의 Likelihood에 대해서, MLE를 거치면,
Distribution을 알 수 없으므로, 이에 대해 여러 분포가 섞인 것으로 가정한다면, 복잡한 형태의 분포가 나타나게 된다.
- : latent varaible
- : paramater, 확률 분포 에 대한 parameter가 된다.
만약 가 지수 함수 등의 꼴로 나타난다면, 이에 대한 Sum이므로 편미분을 통해 Convex optimzation이 불가능한 문제가 나타난다.
이외에도 Mixture 모델 등이 가정 되었다면, 보통 편미분을 해서 해결 불가능한 꼴인 경우가 많다.
solution
: Baum's Q-function. Log Likelihood의 **Auxiliary funciton(보조함수)**가 된다.
즉, : Expectation을 Maximization하는 방법을 변환하여 Likelihood를 최대화 시킨다.
**최적의 를 찾는 것은 를 최대화 시키는 것과 같다. ** 이는, 에서 가 관측될 Likelihood를 최대화시키는 것이다.
Property of Baum's Q-function
- : 가 주어질 때 의 확률 분포 하에서의 Expectation을 의미한다. 의 모든 경우에 대해, 가 발생할 확률을 곱한 weighted sum이라고 할 수 있다.
- If , then : Jensen's inequality에 의해 성립하게 된다.
두 번째 특성은, 의 수렴 값을 찾기 위해 반복하는 과정에서 likelihood의 증가함을 의미한다.
이는 다음과 같이 증명 될 수 있다.
라는 식에 대하여, 아래의 식이 성립한다.
Baum's Q function는 다음과 같이 풀어진다.
는 Bayes' Theorem에 의해 다음과 같아지므로 다음의 식을 대입하면
양 변의 를 곱해 없애주면:
Jensen's Inequality에 의하여 최종적으로:
E-steps
기댓값을 찾는 과정.
, 라고 가정할 때, Q function은 다음과 같아진다.
를 통해 기댓값을 찾는다. 가 주어졌을 때, 새로운 를 사용햇을 때 Likelihood의 Expectation 를 정의한다.
M-steps
를 최대화 하는 과정.
와 가 수렴할 때까지 E-step과 M-step을 반복한다. 이 과정에서, Likelihood가 상승하다가 수렴하게 되면서, Likelihood의 최댓값을 찾을 수 있다.
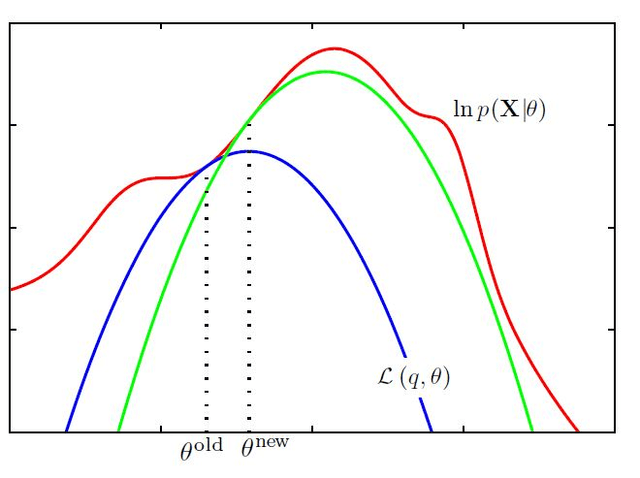
- 는, 다음 E-Step의 가 된다.
- 맨 초기의 는, 임의의 값 혹은 다른 방법 등을 이용해 설정한다.
For MVN: (Guassian Mixture Model=GMM)
:라는 확률 분포가, 여러 개의 Gaussian Distribution의 Mixture라고 본다. 는 Mixture의 개수, 는 해당 Guassian Mixture에 속할 확률이 된다.
- : mixture component, or group, cluster. **번째 클러스터를 의미한다.
- : 속할 확률이자, mixture proportion(특정 data point는 여러 개의 guassian mixture에 속할 수 있다.), mixture weight
- : component density,
- : 인지에 대한 One-hot vector, 와 일대일 매칭되는 Latent Variable이라고 할 수 있다.
이 때, 사용 되는 probablity distribution 에 대해
- =
- =
정확히, 는 로 정의된다.
Q-function
이 때, 와 관련 없는 항은 Expectation에서 분리된다.
이 때, 는, 가 주어질 때 일 확률과 같다.
따라서 : posterior에서 likehood Prior로의 전환으로 볼 수 있다.
는, label을 명백히 알 수 없으므로 어떠한 명백한 discrete 값 대신 확률로 Categoricla Distrubition과 비슷한 MLE를 진행하는 것으로도 해석 가능하다.
즉, 각 Data Point 가 어떤 확률로 에 속할지에 대한 Posterior와 같다.
Get Parameter
:와 같은, Lagrange Multiplier를 통한 Optimization 문제로 변환하자.
- : 와 관련 없으므로 생략한다.
- : 해당 Data들이 에 속할 확률(예측)을 나타낸다.
first parameter:
:: 위 두 조건을 연립하여 나오는 식이 된다.
second, third paramter:
이 때, 는 Symmetric-semi-positive-definite되므로 이 쉽게 계산될 수 있다.
Eigen decomposition을 진행했을 때, : 이 때의 를 구하면
이므로, 이의 역수를 구하면 바로 계산된다.